fields parameter, or use an already defined metadata template.
To learn more about creating templates, see Creating metadata templates in the Admin Console or use the . You can also autofill metadata in templates using our Standard or Enhanced Extraction Agent.
Supported file formats
The endpoint supports the following file formats:Documents
Documents
- DOC
- DOCX
- GDOC
- ODT
- Box Note
- TEXT
- RTF
- XDW
- AS
Images
Images
- TIFF
- TIF
- PNG
- JPEG
- JPG
- WEBP
Spreadsheets
Spreadsheets
- PPT
- PPTX
- GSLIDE
- GSLIDES
- ODP
- OTP
- XLS
- XLSX
- XLSM
- ODS
- CSV
Code Files
Code Files
- Languages:
.js,.py,.css,.php,.sql - JSON
- HTML
- XML
- MD
Supported languages
Box AI can extract metadata from documents in the following languages:- English
- Japanese
- Chinese
- Korean
- Cyrillic-based languages (such as Russian, Ukrainian, Bulgarian, and Serbian)
Before you start
Make sure you followed the steps listed in to create a platform app and authenticate.Send a request
To send a request, use thePOST /2.0/ai/extract_structured endpoint.
Parameters
To make a call, you must pass the following parameters. Mandatory parameters are in bold. Theitems array must contain exactly one element. For prompt and file limits, see .
struct and table field types
The Box AI extract_structured API supports two complex field types — struct and
table in addition to the existing scalar types (string, float, date, enum,
multiSelect).
The struct and table types allow you to extract grouped and repeating structured
data from documents.
struct field type
Use the struct type to group multiple related sub-fields into a single named JSON object.
This is useful when you want to extract a set of related values that belong together and
receive them as one structured object rather than separate flat fields.
Example: an address or a person’s contact details.
A struct field requires a fields array that defines its sub-fields. Each sub-field is an
object with the following properties:
key: The unique identifier for the sub-field.type: The type of the sub-field. Supported types arestring,text,number,float,boolean,date,enum,multiSelect, andarray[<simple_type>](e.g.array[string]). Nestedstructortabletypes are not supported as sub-fields.displayName: The display name of the sub-field.description: A description of the sub-field.prompt: Additional context about the sub-field that can include how to find and format it.
struct field type
table field type
Use the table type to extract repeating rows of structured data as an array of JSON objects,
where each object represents one row.
This is useful when a document contains multiple instances of the same data structure,
for example: line items in an invoice or entries in a tax table.
A table field requires a fields array that defines the columns (sub-fields) of each row.
The sub-field properties and supported types are identical to those of struct.
The output is an array of JSON objects, where each object represents one extracted row.
Example request for the table field type
Supported sub-field types
The following types are supported within both struct and table fields.Tutorial: Turn supplier agreements into structured procurement data
See the
struct and table field types in action. Extract grouped vendor details and a repeating delivery schedule from a supplier agreement, then map the result to a downstream procurement record.Use cases
This example shows you how to extract metadata from a sample invoice in a structured way. Let’s assume you want to extract the vendor name, invoice number, and a few more details.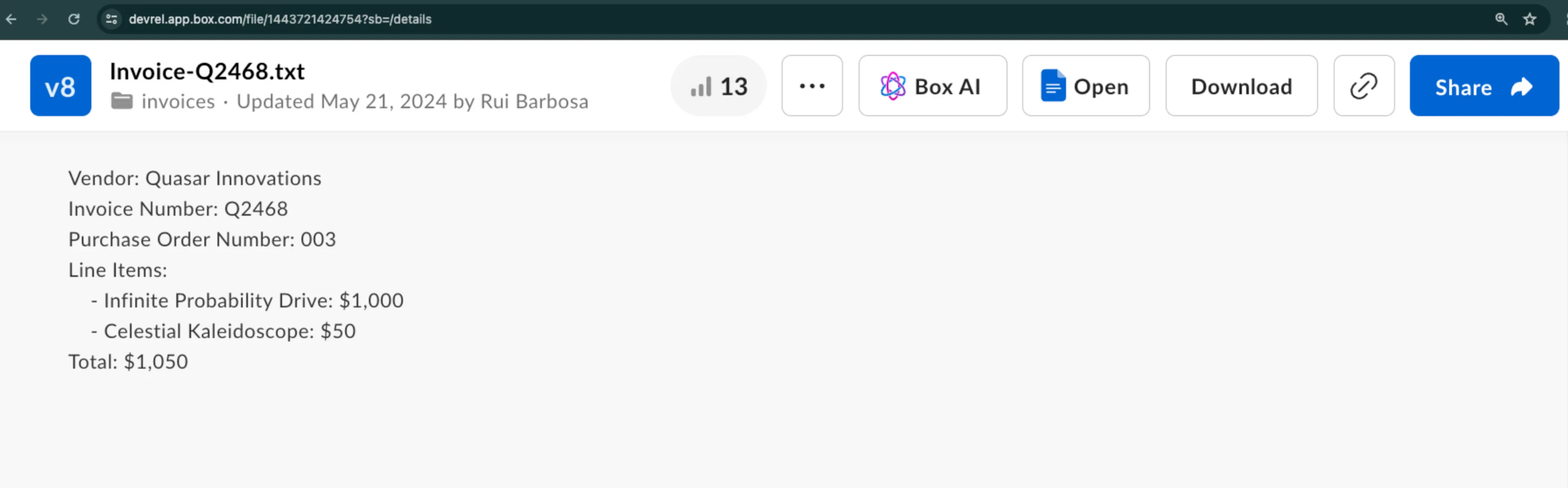
Create the request
To get the response from Box AI, callPOST /2.0/ai/extract_structured endpoint with the following parameters:
items.typeanditems.idto specify the file to extract the data from.fieldsto specify the data that you want to extract from the given file.metadata_templateto supply an already existing metadata template.
You can use either
fields or metadata_template to specify your structure, but not both.Use fields parameter
The fields parameter allows you to specify the data you want to extract. Each fields object has a subset of parameters you can use to add more information about the searched data.
For example, you can add the field type, description, or even a prompt with some additional context.
Use metadata template
If you prefer to use a metadata template, you can provide itstemplate_key, type, and scope.
Enhanced Extract Agent
To use the Enhanced Extract Agent, specify theai_agent object as follows:
- Inline field definitions (best when fields change frequently)
- Metadata template (best when fields stay consistent)
Tutorial: Automate invoice intake with Box AI Extract
See structured extraction in action. Build an end-to-end automation that watches a folder, extracts invoice fields, and writes metadata back to each file.